MySQL分库分表
什么是分库分表?
一般来说数据表写到两千万条数据之后,底层 B+ 树的层级结构就可能会变高,不同层级的数据页一般都放在磁盘里不同的地方,磁盘 IO 就会增多,查询性能就会变差。这个时候我们就会考虑分库分表。分表分为水平分表和垂直分表。而分库则是将一个库的数据拆分到多个相同的库中,访问的时候访问一个库。
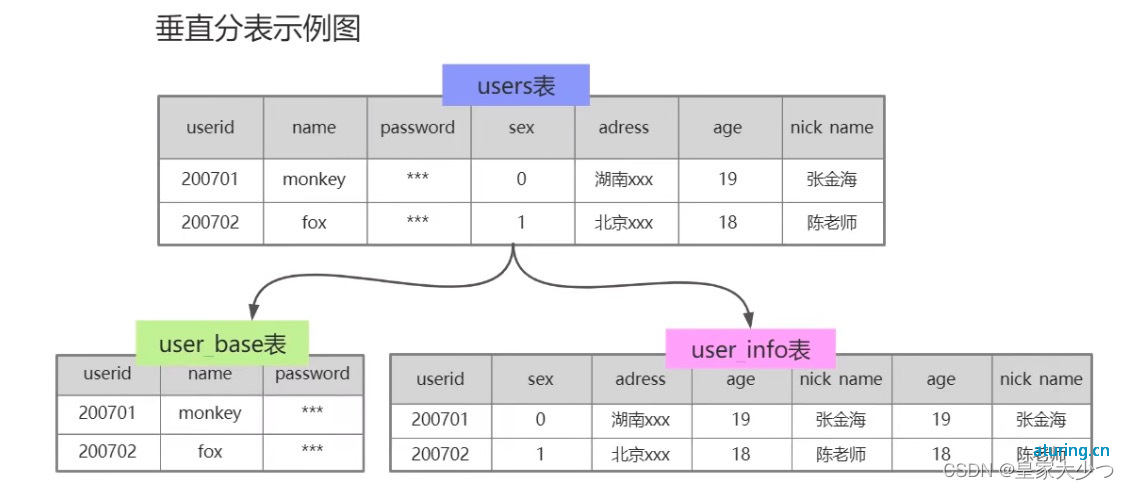
垂直分表
垂直分表的原理比较简单,一般就是把某几列拆成一个新表,这样单行数据就会变小, B+ 树里的单个数据页(固定 16KB)内能放入的行数就会变多,从而使单表能放入更多的数据。
水平分表
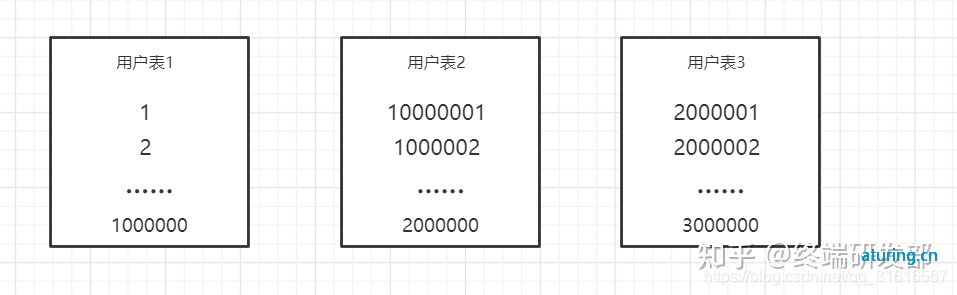
举例一张订单users大表,变成读写 user_1、user_2、... 、user_n 这样的 N 张小表。
根据 id 范围分表
一般来说是最好用的,是根据 id 范围进行分表。假设每张分表能放两千万行数据,这里举例。
- user0 放主键 id 为 1~2千万的数据;
- user1 定 id 为 两千万 +1 ~ 4千万;
- user2 定 id 为 4千万 +1 ~ 6千万;
- userN 放 2N千万+1 ~ 2(N+1)千万。 假设现在有条数据,id=3 千万,将这个 3 千万除 2 千万= 1.5,向下取整得到 1,那就可以得到这条数据属于 user1 表。
根据 id 取模分表
提前约定好表数量,比如5张表,分别是 user0 到 user4,当一个 id=31 进来,对 31%5=1,取模得 1,于是就能知道应该读写 user1 表。这里优点是分摊均匀,缺点是扩展麻烦,一般提前分很多表看着很多空表。
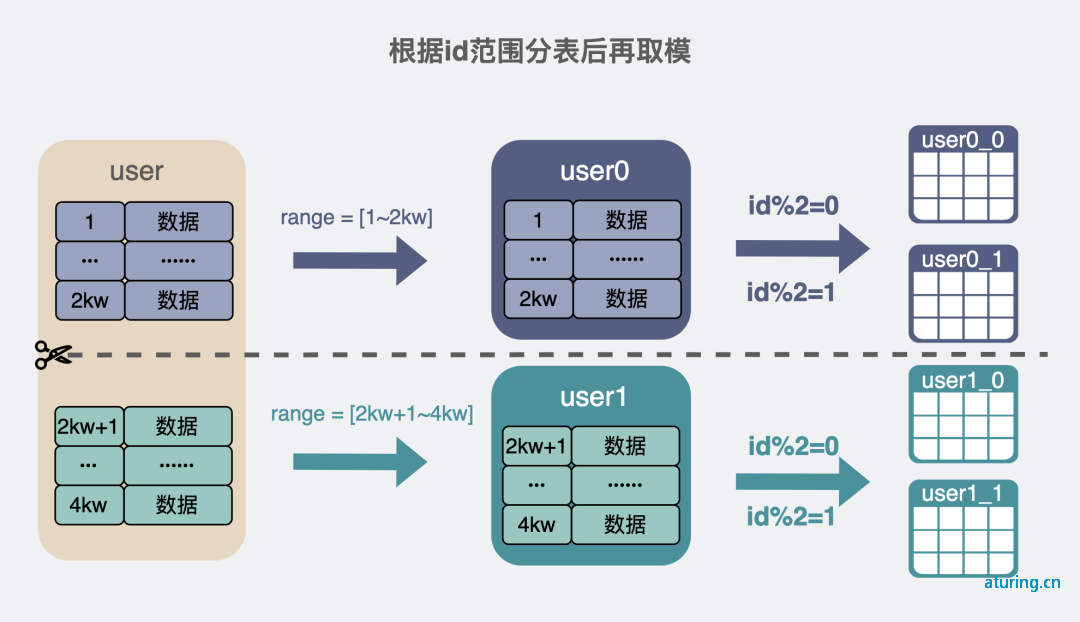
id 范围id 取模结合分表
我们可以在某个 id 范围里,引入取模的功能。比如 2千万~4千万 是 user1 表。现在可以在这个范围再分成 5 个表,也就是引 入user1-0、user1-2 到 user1-4,在这 5 个表里取模。举个例子,id=3千万,根据范围,会分到 user1 表,然后再进行取模 3千万 % 5 = 0,也就是读写 user1-0 表。这样就可以将写单表分摊为写多表。这在分库的场景下优势会更明显。不同的库,可以把服务部署到不同的机器上,这样各个机器的性能都能被用起来。
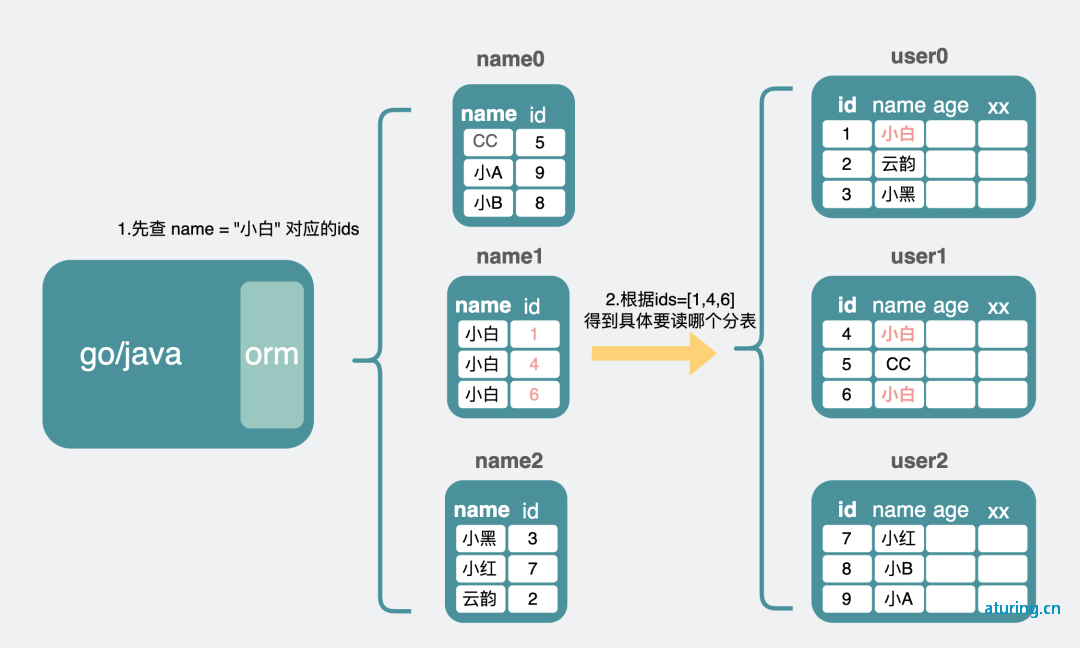
读扩散问题
我们上面提到的好几种分表方式,都用了 id 这一列作为分表的依据,这其实就是所谓的分片键。实际上我们一般也是用的数据库主键作为分片键。这样,理想情况下我们已知一个 id,不管是根据哪种规则,我们都能很快定位到该读哪个分表。但很多情况下,我们的查询又不是只查主键,如果我的数据库表有一列 name,并且加了个普通索引。比如: select * from user where name = "小白" 问题来了,就是无法定位到表。一般的做法是并发同时读取多个分表,随着表越来越多,次数会越来越多,这就是所谓的读扩散问题。 引入新表来做分表 单独建个新的分片表,这个新表里的列就只有旧表的主键 id 和普通索引列,而这次换普通索引列来做分片键。通过新索引表解决读扩散问题。但这样缺点就是需要维护两套表。
分库分表工具
- sharding-sphere:jar,前身是sharding-jdbc;
- TDDL:jar,Taobao Distribute Data Layer;
- Mycat:中间件。
Mycat介绍 MyCat 是目前最流行的基于 java 语言编写的数据库中间件,是一个实现了 MySQL 协议的服务器,前端用户可以把它看作是一个数据库代理,用 MySQL 客户端工具和命令行访问,而其后端可以用 MySQL 原生协议与多个 MySQL 服务器通信,也可以用 JDBC 协议与大多数主流数据库服务器通信,其核心功能是分库分表。配合数据库的主从模式还可实现读写分离。 MyCat 是基于阿里开源的 Cobar 产品而研发,Cobar 的稳定性、可靠性、优秀的架构和性能以及众多成熟的使用案例使得 MyCat 变得非常的强大。 实战 将不同的表分布在不同的库中,但是访问的时候使用的是同一个mycat的终端,这些操作其实很简单,都是由mycat来完成的,我们需要做的事情就是修改几个简单的配置即可。 测试表
CREATE TABLE customer(
id INT AUTO_INCREMENT,
NAME VARCHAR(200),
PRIMARY KEY(id)
);
CREATE TABLE orders(
id INT AUTO_INCREMENT,
order_type INT,
customer_id INT,
amount DECIMAL(10,2),
PRIMARY KEY(id)
);
分库配置数据库节点 schema.xml
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1">
<table name = "customer" dataNode="dn2"></table>
</schema>
<dataNode name="dn1" dataHost="host1" database="orders" />
<dataNode name="dn2" dataHost="host2" database="orders"/>
<dataHost name="host1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="192.168.85.111:3306" user="root"password="123456"></writeHost>
</dataHost>
<dataHost name="host2" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1" sla
veThreshold="100"> <heartbeat>select user()</heartbeat>
<writeHost host="hostM2" url="192.168.85.113:3306" user="root" password="123456"></writeHost>
</dataHost>
</mycat:schema>
分表配置 修改schema.xml
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1">
<table name = "customer" dataNode="dn2"></table>
<table name ="orders" dataNode="dn1,dn2" rule="mod_rule"></table>
</schema>
rule.xml
<tableRule name="mod_rule">
<rule>
<!-- 分片字段-->
<columns>customer_id</columns>
<!-- 分片算法名 -->
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
<function name="mod-long" class="io.mycat.route.function.Part
itionByMod"> <!-- how many data nodes -->
<property name="count">2</property>
</function>
全局表 在分片的情况下,当业务表因为规模而进行分片之后,业务表与这个字典表的之间关联会变得比较棘手,因此,在mycat中存在一种全局表,他具备以下特性: 1、全局表的插入、更新操作会实时的在所有节点上执行,保持各个分片的数据一致性 2、全局表的查询操作,只从一个节点获取 3、全局表可以跟任何一个表进行join操作 常用分片规则 取模运算 约定表字段和数量,上面的例子,id/分表数量=表,如,31%5=1 范围分片 约定范围值及对应的节点。
云原生分布式数据库PolarDB-X
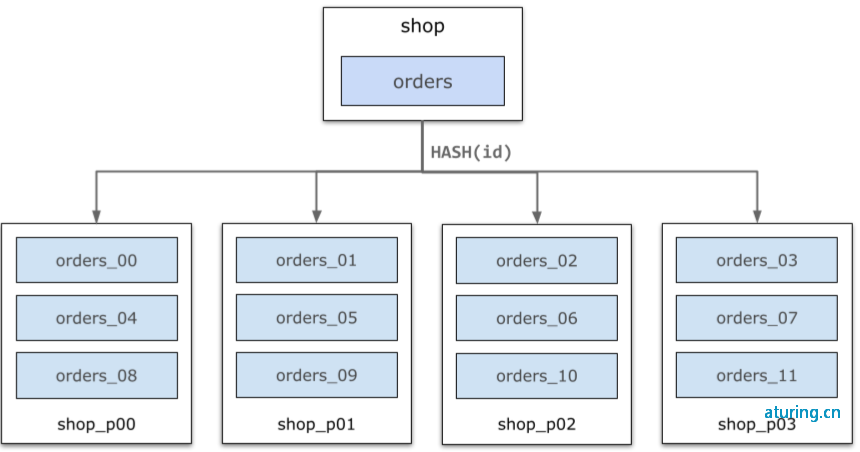
PolarDB-X将数据表以水平分区的方式,分布在多个存储节点(DN)上。数据分区方式由分区函数决定,PolarDB-X支持哈希(Hash)、范围(Range)等常用的分区函数。以下图为例,shop库中的orders表根据每行数据的ID属性进行哈希,被分区水平切分成orders_00~orders_11共计12个分区,均匀分布在4个数据节点上。PolarDB-X的分布式SQL层将会自动完成查询路由、结果合并等。
适用场景
高负载低延时交易 交易场景广泛存在于互联网业务中,交易系统是信息系统中最为核心的组件之一。业务连续性、事务一致性和系统安全性是交易系统正常运行的基础,长时间高负载低延时的运行是互联网时代交易系统的发展方向。 大峰谷差流量 大峰谷差是指特定周期内系统峰值负载是谷值负载的20倍以上的系统访问场景,该场景多见于“秒杀”、“拼团”和“限时优惠”相关业务中。系统管理员常陷于容量安全与成本控制之间的两难,所以成本优化方案和平滑扩缩容能力是该场景的核心诉求。
我们目前用到的
- 按年按月分表
- hash分表
- id范围分表 参考文档 http://www.mycat.org.cn/
- 上一篇: laravel队列基本使用
- 下一篇: MySQL慢查分析
如果您喜欢我的文章,请点击下面按钮随意打赏,您的支持是我最大的动力。
最新评论