MySQL的底层原理与索引结构选择
MySQL是一种流行的开源关系型数据库管理系统,它的设计和实现包含了许多复杂的底层原理。在这些原理中,索引结构的选择对于数据库性能有着至关重要的影响。本文将详细介绍MySQL的底层原理,并解释为什么MySQL的索引结构默认使用B+Tree,而不是其他如B-Tree、Hash、二叉树或红黑树。
MySQL的底层原理
MySQL的架构可以分为几个主要层次,包括连接器、查询解析器、优化器、执行器和存储引擎。这些层次协同工作,处理用户的SQL请求,并返回查询结果。
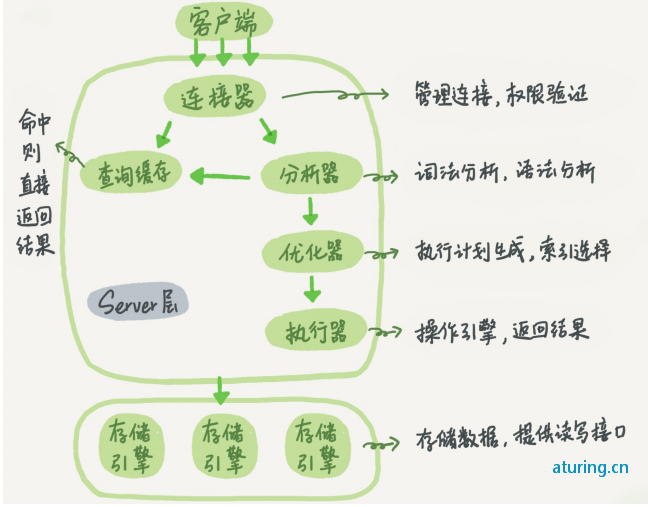
连接器(Connector)
连接器负责与客户端建立连接,进行身份验证,并处理连接的关闭。
查询解析器(Parser)
查询解析器接收来自客户端的SQL语句,解析并生成抽象语法树(AST)。然后,它将AST转换为逻辑查询计划。
优化器(Optimizer)
优化器接收逻辑查询计划,并决定最有效的执行策略。它可能会重写查询,选择不同的索引,或者决定是否使用临时表等。
执行器(Executor)
执行器根据优化器的决策执行查询计划。它从存储引擎中读取数据,并将结果返回给客户端。
存储引擎(Storage Engine)
存储引擎是MySQL的核心组件,负责数据的存储、检索和管理。InnoDB是MySQL中最常用的存储引擎,它提供了事务支持、行级锁定和外键约束等功能。
索引结构的选择
在数据库中,索引是用来加速数据检索的数据结构。MySQL支持多种索引类型,包括B-Tree、Hash、Full-text等。然而,InnoDB存储引擎默认使用B+Tree作为索引结构。下面是为什么选择B+Tree的原因。
B+Tree的优势
磁盘读写效率
B+Tree是一种平衡树结构,它将数据分布在多个层级中。在磁盘上,B+Tree的这种结构可以减少磁盘I/O操作,因为每次查找只需要读取少量的磁盘块。
范围查询
B+Tree非常适合处理范围查询,因为它的节点是有序的。这使得数据库可以快速地遍历一个范围内的所有数据,而不需要逐个比较。
高效的插入和删除
B+Tree在插入和删除操作时,可以通过分裂和合并节点来保持树的平衡。这种操作相对高效,因为它不需要重新排序大量的数据。
空间局部性
B+Tree的叶子节点形成了一个链表,这意味着相邻的数据项在物理存储上也是相邻的。这种空间局部性对于缓存效率和数据访问速度非常有利。
为什么不是其他结构?
B-Tree
B-Tree与B+Tree类似,但它的每个节点都存储数据。这导致了B-Tree在处理大量数据时,可能需要更多的磁盘块来存储相同的数据集。因此,B+Tree在磁盘读写效率上更胜一筹。
Hash
Hash索引提供了非常快的查找速度,但它不适合范围查询和排序操作。此外,Hash索引需要额外的存储空间来处理哈希冲突,而且在数据量大时,性能可能会下降。
二叉树
二叉树在最坏情况下可能非常不平衡,导致查找效率低下。虽然可以通过自平衡二叉搜索树(如AVL树)来解决这个问题,但这些操作会增加额外的开销。
红黑树
红黑树是一种自平衡的二叉搜索树,它在插入和删除操作时可以保持平衡。然而,红黑树在处理范围查询时不如B+Tree高效,因为它的节点不是有序的。
B 树/B+树
B树(Balanced Tree)和B+树是用于数据存储和检索的常见数据结构,它们在MySQL数据库中广泛使用,特别是在InnoDB存储引擎中。
-
B树(Balanced Tree)
- 概念:B树是一种自平衡的多路搜索树,可以存储和检索大量数据。在B树中,所有的叶子节点都在同一层,并且每个非叶子节点都可以有多个孩子节点,每个节点都包含关键字及其对应的数据。
- 特性:B树的搜索、插入和删除操作的时间复杂度都是O(logN),其中N是树中元素的数量。这使得B树特别适合处理大量数据的情况。
-
B+树
- 概念:B+树是B树的一种扩展,也是一种自平衡的多路搜索树。与B树不同,B+树的所有非叶子节点不存储数据,只存储关键字,所有的数据都存储在叶子节点中。
- 特性:由于非叶子节点不存储数据,B+树的非叶子节点可以存储更多的关键字,因此B+树的高度通常比B树低,这使得B+树对于大量数据的检索更加高效。另外,B+树的叶子节点之间通过指针相连,这使得范围查询更加方便。
B树与B+树的区别主要体现在以下几个方面:
- 数据存储位置:在B树中,数据可以存储在所有节点中;而在B+树中,数据只存储在叶子节点中。
- 节点结构:B树的每个节点包含关键字和对应的数据,而B+树的非叶子节点只包含关键字,不包含数据,所有数据都在叶子节点中。
- 查询效率:由于B+树的高度通常比B树低,因此B+树的查询效率更高;同时,B+树的叶子节点之间通过指针相连,这使得范围查询更加高效。
- 空间利用率:由于B+树的非叶子节点不存储数据,因此每个节点可以存储更多的关键字,这使得B+树的空间利用率更高。
结论
MySQL的底层原理和索引结构的选择都是为了优化数据库的性能。B+Tree作为InnoDB存储引擎的默认索引结构,它在磁盘读写效率、范围查询、插入和删除操作以及空间局部性方面都表现出色。这些特性使得B+Tree成为关系型数据库中理想的索引结构。
- 上一篇: SonarQube和GitLab使用
- 下一篇: golang字符串4种拼接方式对比
如果您喜欢我的文章,请点击下面按钮随意打赏,您的支持是我最大的动力。
最新评论