Golang Channel源码解析
1. 概述
Golang官方对 chan 的描述如下:
A channel provides a mechanism for concurrently executing functions to communicate by sending and receiving values of a specified element type. The value of an uninitialized channel is nil.
chan 提供了一种并发通信机制,用于生产和消费某一指定类型数据,未初始化的 chan 的值是 nil。
2. 特性与实现
Chan 是 Go 里面的一种数据结构,具有以下特性:
- goroutine-safe,多个 goroutine 可以同时访问一个 channel 而不会出现并发问题
- 可以用于在 goroutine 之间存储和传递值
- 其语义是先入先出(FIFO)
- 可以导致 goroutine 的 block 和 unblock
内部结构
chan 内部结构如下图:
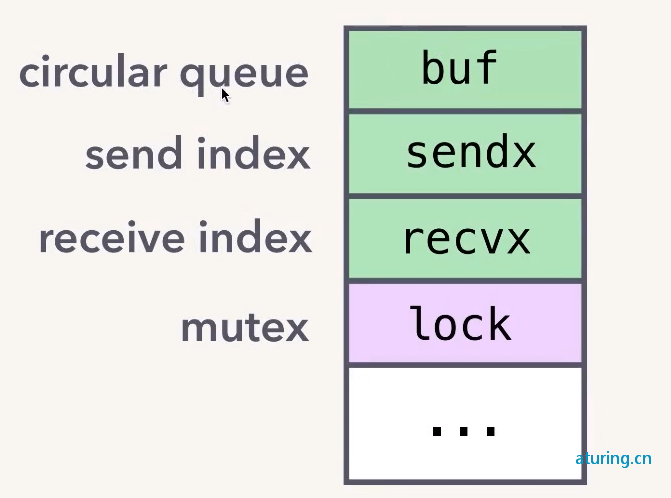
主要包含以下几个部分:
- circular queue:循环队列,用于存储数据
- send index 记录发送的位置
- receive index 记录接收的位置
- mutex 锁,用于实现 goroutine-safe
buf 的具体实现很简单,就是一个环形队列,使用 sendx 和 recvx 分别用来记录发送、接收的 offset,然后通过 mutex 互斥锁来保证并发安全。
创建 chan
chan 使用 make 进行初始化,第一个参数指定 chan 中的元素类型,第二个参数用于指定 chan 的缓冲区大小。
ch := make(chan string, 3)
上述代码中 make 返回的 ch 实际上是一个指向 heap 中真正的 chan 对象的指针。
chan(即 hchan 结构体)默认会被分配在堆上,make 返回的只是一个指向该对象的指针。这也是为什么我们可以在函数之间传递 chan,而不是 chan 的指针。
发送、接收与关闭
func main() {
ch := make(chan Task, 3)
for _, task := range hellaTasks {
taskCh <- task // 发送
}
close(taskCh) // 关闭
}
func worker(ch chan Task) {
for {
task := <-taskCh // 接收
process(task)
}
}
main goroutine 发送 task 到 chan,然后 worker goroutine 从 chan 中接收 task 并处理,最后 main goroutine 发送完成后关闭 chan。
具体发送过程如下:
- acquire 加锁
- enqueue,将
task对象拷贝到数组里 - release 释放锁
对于 chan 的关闭,最佳实践是由发送方进行关闭。
接收过程:
- acquire 加锁
- dequeue
- 将
task对象从数组中拷贝出来赋值给用户用于接收的对象 -
task := <-taskCh,比如这里就是拷贝出来赋值给task
- 将
- release 释放锁
整个过程中没有任何共享内存,数据都是通过 copy 进行传递。这遵循了 Go 并发设计中很核心的一个理念:
Do not communicate by sharing memory; instead, share memory by communicating.
阻塞与唤醒
hchan 中的 buf 数组大小就是 make chan 时指定的大小。
当 buf 满之后再往 chan 中发送值就会阻塞。
复习一下 goroutine 调度:
G 阻塞之后并不会阻塞 M。M 会先把这个 G 暂停(gopark),然后把执行栈切换到 g0,g0 会执行 schedule() 函数,从当前 M 绑定的 P 中查找有没有可以执行的 G,有就捞出来继续执行。
先发后收
假设 chan 中已经有 3 个 task 了,然后我们再试着往里面发送一个
taskCh <- task
runtime 会调用 gopark 将这个 goroutine(姑且称作 G1)切换到 wait 状态。
什么时候会被唤醒呢?
hchan 结构体中还有 sendq、recvq 两个列表,分别记录了等待发送或者接收的 goroutine,如下图所示:
type hchan struct {
recvq waitq // list of recv waiters
sendq waitq // list of send waiters
}
type waitq struct {
first *sudog
last *sudog
}
比如前面被阻塞的 G1 就会存入 sendq
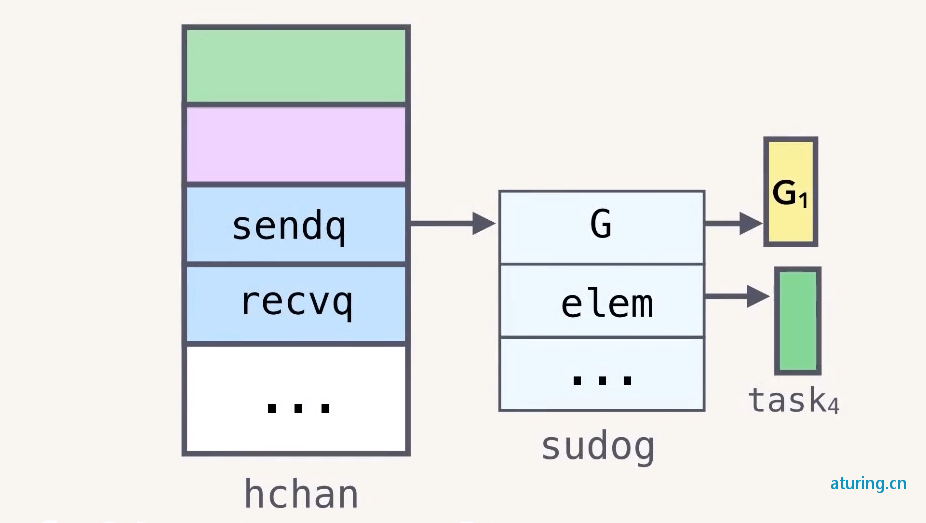
假设此时 G2 从 chan 中取走一个消息
task := <-taskCh
G2 取走一个消息后就会找到 sendq 中的第一个对象,把待发送的 elem 直接写入 buf 数组。然后调用 goready 把对应的 goroutine G1 设置为 runnable 状态。
先收后发
之前是先发送,后接收。现在看一下先接收后发送的情况。
task := <-taskCh
G2 直接从空的 chan 中取消息,同样会被阻塞,然后被写入到 hchan 的 recvq 中。
注意:
elem 这里的 t 存的是 G2 栈里的地址。
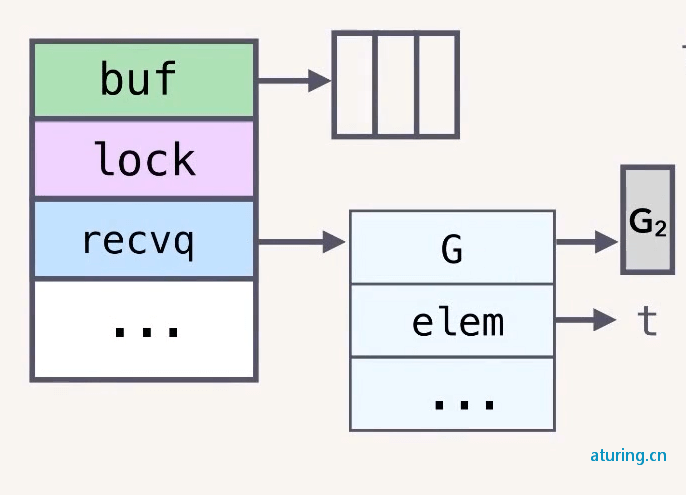
然后 G1 往 chan 中发送一条消息。
taskCh <- task
按照上面的逻辑应该是,将 task 写入 buf 数组后,再把 recvq 中的第一个 goroutine G2 唤醒。
但是 Go 官方这里进行了优化,可以说是一个骚操作。因为 recvq 里的 elem 对象 t 存的就是接收者的内存地址。
所以我们可以直接把 G1 发送来的 task 写入 elem 对应的 t 里,即在 G1 里修改 G2 的栈对象。
因为这个时候 G2 还是 gopark,处于 waiting 状态,所以不会出问题。
正常情况下因为不知道两个线程谁先谁后,这样改肯定会出问题。但是在 Go runtime 这里,肯定是 G2 先执行,满足 happen-before 所以不存在问题。
通过这样一个骚操作省去了发送和接收时的两次加解锁和内存拷贝。
特性实现原理
到此我们应该明白了 chan 的这些特性的实现原理:
- goroutine-safe:
hchanmutex,通过加锁来避免数据竞争 - 可以用于在 goroutine 之间存储和传递值,以及先入先出(FIFO)语义:copying into and out of
hchanbuffer - 可以导致 goroutine 的 block 和 unblock:通过
sudog queues来记录阻塞的 goroutine,通过runtime scheduler(gopark,goready)来实现阻塞与唤醒
3. 源码分析
chan 的所有相关代码都在 runtime/chan.go 中,还是比较好找的。
内部结构
type hchan struct {
qcount uint // total data in the queue
dataqsiz uint // size of the circular queue
buf unsafe.Pointer // points to an array of dataqsiz elements
elemsize uint16
closed uint32
elemtype *_type // element type
sendx uint // send index
recvx uint // receive index
recvq waitq // list of recv waiters
sendq waitq // list of send waiters
// lock protects all fields in hchan, as well as several
// fields in sudogs blocked on this channel.
//
// Do not change another G's status while holding this lock
// (in particular, do not ready a G), as this can deadlock
// with stack shrinking.
lock mutex
}
type waitq struct {
first *sudog
last *sudog
}
其中的 sendx/recvx、sendq/recvq、buf 以及 lock 是核心字段。
创建
在源码中通道的创建由 makechan 方法实现:
func makechan(t *chantype, size int) *hchan {}
然后还有两个包装方法:
//go:linkname reflect_makechan reflect.makechan
func reflect_makechan(t *chantype, size int) *hchan {
return makechan(t, size)
}
func makechan64(t *chantype, size int64) *hchan {
if int64(int(size)) != size {
panic(plainError("makechan: size out of range"))
}
return makechan(t, int(size))
}
内部都是调用的 makechan 方法。
func makechan(t *chantype, size int) *hchan {
elem := t.elem
// 编译器检查 typesize 和 align
if elem.size >= 1<<16 {
throw("makechan: invalid channel element type")
}
if hchanSize%maxAlign != 0 || elem.align > maxAlign {
throw("makechan: bad alignment")
}
// 计算存放数据元素的内存大小以及是否溢出
mem, overflow := math.MulUintptr(elem.size, uintptr(size))
if overflow || mem > maxAlloc-hchanSize || size < 0 {
panic(plainError("makechan: size out of range"))
}
var c *hchan
switch {
case mem == 0:
// chan的size为0,或者每个元素占用的大小为0(比如struct{}大小就是0,不占空间)
// 这种情况就不需要单独为buf分配空间
c = (*hchan)(mallocgc(hchanSize, nil, true))
c.buf = c.raceaddr()
case elem.ptrdata == 0:
// 如果队列中不存在指针,那么每个元素都需要被存储并占用空间,占用大小为前面乘法算出来的mem
// 同时还要加上hchan本身占用的空间大小,加起来就是整个hchan占用的空间大小
c = (*hchan)(mallocgc(hchanSize+mem, nil, true))
// 把buf指针指向空的hchan占用空间大小的末尾
c.buf = add(unsafe.Pointer(c), hchanSize)
default:
// 如果chan中的元素是指针类型的数据,为buf单独开辟mem大小的空间,用来保存所有的数据
c = new(hchan)
c.buf = mallocgc(mem, elem, true)
}
// 元素大小、类型以及缓冲区大小赋值
c.elemsize = uint16(elem.size)
c.elemtype = elem
c.dataqsiz = uint(size)
// 初始化锁
lockInit(&c.lock, lockRankHchan)
return c
}
具体流程如下:
- 首先是编译器检查,包括通道元素类型的 size 以及通道和元素的对齐,然后计算存放数据元素的内存大小以及是否溢出
- 然后根据不同条件进行内存分配
总体的原则是:总内存大小 = hchan 需要的内存大小 + 元素需要的内存大小
- 队列为空或元素大小为0:只需要开辟的内存空间为
hchan本身的大小 - 元素不是指针类型:需要开辟的内存空间=
hchan本身大小 + 每个元素的大小 * 申请的队列长度 - 元素是指针类型:这种情况下
buf需要单独开辟空间,buf占用内存大小为每个元素的大小 * 申请的队列长度
- 最后则对
chan的其他字段赋值
发送
发送数据到 channel 时,直观的理解是将数据放到 chan 的环形队列中,不过 go 做了一些优化:
- 先判断是否有等待接收数据的 groutine,如果有,直接将数据发给 Groutine,就不放入队列中了。
- 这样省去了两次内存拷贝和加锁的开销
- 当然还有另外一种情况就是:队列如果满了,那就只能放到队列中等待,直到有数据被取走才能发送。
调用链
chan 的发送逻辑涉及到 5 个方法:
func selectnbsend(c *hchan, elem unsafe.Pointer) (selected bool) {}
func chansend1(c *hchan, elem unsafe.Pointer) {…}
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool {…}
func send(c *hchan, sg *sudog, ep unsafe.Pointer, unlockf func(), skip int) {…}
func sendDirect(t *_type, sg *sudog, src unsafe.Pointer) {…}
chansend1 方法是 go 编译代码中 c <- x 这种写法的入口点,即当我们编写代码 c <- x 其实就是调用此方法。 这四个方法的调用关系:chansend1 -> chansend -> send -> sendDirect。
具体发送逻辑在 chansend 这个方法里,然后真正使用的方法其实是对该方法的一层包装。
func chansend1(c *hchan, elem unsafe.Pointer) {
chansend(c, elem, true, getcallerpc())
}
func selectnbsend(c *hchan, elem unsafe.Pointer) (selected bool) {
return chansend(c, elem, false, getcallerpc())
}
chansend
核心逻辑:
- 如果
recvq不为空,从recvq中取出一个等待接收数据的 Groutine,直接将数据发送给该 Groutine - 如果
recvq为空,才将数据放入buf中 - 如果
buf已满,则将要发送的数据和当前的 Groutine 打包成sudog对象放入sendq,并将 groutine 置为等待状态- 等 groutine 再次被调度时程序继续执行
send
然后追踪一下 send 方法:
func send(c *hchan, sg *sudog, ep unsafe.Pointer, unlockf func(), skip int) {
// 忽略 race 检查..
if sg.elem != nil {
// 直接拷贝到接受者内存,使用写屏障
sendDirect(c.elemtype, sg, ep)
sg.elem = nil
}
gp := sg.g // 取出 sudog 中记录的 g,这里的 g 就是被阻塞接收者
unlockf()
gp.param = unsafe.Pointer(sg) // 更新接收者 g 的 param 字段,在 recv 方法中会用到
sg.success = true
if sg.releasetime != 0 {
sg.releasetime = cputicks()
}
// 最后把被阻塞的接收者 g 唤醒
goready(gp, skip+1)
}
sendDirect
继续看 sendDirect 方法:
func sendDirect(t *_type, sg *sudog, src unsafe.Pointer) {
// src 在当前 goroutine 的栈上,dst 是另一个 goroutine 的栈
// 直接进行内存"搬迁"
// 如果目标地址的栈发生了栈收缩,当我们读出了 sg.elem 后
// 就不能修改真正的 dst 位置的值了
// 因此需要在读和写之前加上一个屏障
dst := sg.elem
typeBitsBulkBarrier(t, uintptr(dst), uintptr(src), t.size)
// 拷贝内存
memmove(dst, src, t.size)
}
这里涉及到一个 goroutine 直接写另一个 goroutine 栈的操作,一般而言,不同 goroutine 的栈是各自独有的。而这也违反了 GC 的一些假设。为了不出问题,写的过程中增加了写屏障,保证正确地完成写操作。这样做的好处是减少了一次内存 copy:不用先拷贝到 channel 的 buf,直接由发送者到接收者,没有中间商赚差价,效率得以提高,完美。
接收
从 channel 读取数据的流程和发送的类似,基本是发送操作的逆操作。
这里同样存在和 send 一样的优化:从 channel 读取数据时,不是直接去环形队列中去数据,而是先判断是否有等待发送数据的 groutine。如果有,直接将 groutine 出队列,取出数据返回,并唤醒 groutine。如果没有等待发送数据的 groutine,再从环形队列中取数据。
调用链
chan 的接收涉及到 7 个方法:
func reflect_chanrecv(c *hchan, nb bool, elem unsafe.Pointer) (selected bool, received bool) {}
func selectnbrecv(elem unsafe.Pointer, c *hchan) (selected, received bool) {}
func chanrecv1(c *hchan, elem unsafe.Pointer) {…}
func chanrecv2(c *hchan, elem unsafe.Pointer) (received bool) {…}
```markdown
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {…}
func recv(c *hchan, sg *sudog, ep unsafe.Pointer, unlockf func(), skip int) {…}
func recvDirect(t *_type, sg *sudog, dst unsafe.Pointer) {…}
按照发送时的套路可知,只有 chanrecv 是具体逻辑,上面几个都是包装方法:
//go:linkname reflect_chanrecv reflect.chanrecv
func reflect_chanrecv(c *hchan, nb bool, elem unsafe.Pointer) (selected bool, received bool) {
return chanrecv(c, elem, !nb)
}
func selectnbrecv(elem unsafe.Pointer, c *hchan) (selected, received bool) {
return chanrecv(c, elem, false)
}
//go:nosplit
func chanrecv1(c *hchan, elem unsafe.Pointer) {
chanrecv(c, elem, true)
}
//go:nosplit
func chanrecv2(c *hchan, elem unsafe.Pointer) (received bool) {
_, received = chanrecv(c, elem, true)
return
}
接收操作有两种写法,一种带 “ok”,反应 channel 是否关闭;一种不带 “ok”,这种写法,当接收到相应类型的零值时无法知道是真实的发送者发送过来的值,还是 channel 被关闭后,返回给接收者的默认类型的零值。两种写法,都有各自的应用场景。经过编译器的处理后,这两种写法最后对应源码里的就是不带 ok 的 chanrecv1 和带 ok 的 chanrecv2 这两个函数。
chanrecv
核心流程:
- 如果
recvq不为空,从recvq中取出一个等待接收数据的 Groutine,直接将数据发给该 Groutine - 如果
recvq为空,才将数据放入buf中 - 如果
buf已满,则将要发送的数据和当前的 Groutine 打包成sudog对象放入sendq,并将 groutine 置为等待状态 - 等 groutine 再次被调度时程序继续执行
recv
然后追踪一下 recv 方法:
func recv(c *hchan, sg *sudog, ep unsafe.Pointer, unlockf func(), skip int) {
// 非缓冲型的 channel
if c.dataqsiz == 0 {
// 并且需要接收值
if ep != nil {
// 直接进行内存拷贝
recvDirect(c.elemtype, sg, ep)
}
} else {
// 需要注意:进入 recv 方法说明 sendq 队列里是有值的
// 那么对缓冲型的 channel 来说,sendq 有值就意味着 buf 满了
// 也就是 recvx 和 sendx 重合了。
// 这里要做的就是先从 buf 中读一个数据出来,然后再把发送者发送的数据写入 buf
qp := chanbuf(c, c.recvx)
// 将接收游标处的数据拷贝给接收者
if ep != nil {
typedmemmove(c.elemtype, ep, qp)
}
// 从发送者把数据写入 recvx
typedmemmove(c.elemtype, qp, sg.elem)
// 然后修改 recvx 和 sendx 的位置
c.recvx++
if c.recvx == c.dataqsiz {
c.recvx = 0
}
c.sendx = c.recvx // c.sendx = (c.sendx+1) % c.dataqsiz
}
sg.elem = nil
gp := sg.g
// 解锁
unlockf()
gp.param = unsafe.Pointer(sg)
sg.success = true
if sg.releasetime != 0 {
sg.releasetime = cputicks()
}
// 最后唤醒发送的 goroutine
goready(gp, skip+1)
}
recvDirect
再看一下 recvDirect:
func recvDirect(t *_type, sg *sudog, dst unsafe.Pointer) {
// 如果是非缓冲型的,就直接从发送者的栈拷贝到接收者的栈。
// 和 sendDirect 一样的需要加内存屏障
src := sg.elem
typeBitsBulkBarrier(t, uintptr(dst), uintptr(src), t.size)
memmove(dst, src, t.size)
}
看了接收部分代码后,整个流程就更新清晰了。根据前面的发送逻辑可以知道,不管是接收还是发送只要被阻塞了,加入到了 sendq 或者 recvq 之后,那么后续的发送或者接收都是由对方进行处理了。
比如接收被阻塞了,当前 g 构成成一个 sudog 然后加入到 recvq,接着调用了 gopark 就已经阻塞了,啥也干不了了。只能等到有发送者来的时候直接从 recvq 里把这个 sudog 取出来,并且直接把要他发送的值拷贝到这个 sudog.elem 字段上,也就是调用 chan 接收方法时传进来的那个值。最后发送方再调用 goready 把这个 g 给唤醒,这样再把剩下的逻辑走完,这个被阻塞了一会的接收者就可以拿着数据返回了。
核心逻辑:
- 如果有等待发送数据的 groutine,从
sendq中取出一个等待发送数据的 Groutine,取出数据 - 如果没有等待的 groutine,且环形队列中有数据,从队列中取出数据
- 如果没有等待的 groutine,且环形队列中也没有数据,则阻塞该 Groutine,并将 groutine 打包为
sudog加入到recvq等待队列中
func closechan(c *hchan){}
关闭
调用链
close 就比较简单了,相关方法就两个:
//go:linkname reflect_chanclose reflect.chanclose
func reflect_chanclose(c *hchan) {
closechan(c)
}
其中一个还是包装方法,真正逻辑就在 closechan 里。每个逻辑都有一个 reflect_xxx 的方法,根据名字猜测是反射的时候用的。
closechan
核心流程:
- 设置关闭状态
- 唤醒所有等待读取
channel的协程 - 所有等待写入
channel的协程,抛出异常
存储实现
chan 内部使用一个环形队列实现存储,使用 sendx 或 recvx 进行发送或读取。
并发安全
使用 mutex 保证并发安全。
调度
使用 sendq 和 recvq 来暂存由于发送或接收而被阻塞的 goroutine。
-
send/recv的时候都会判断recvq/sendq是否有 goroutine 正在等待,有则优先处理。
发送
发送的时候发现 recvq 有 goroutine 正在等待,说明此时 chan 的 buf 是空的,或者 chan 是个非缓存 chan,根本没有 buf。对于发送来说,不管是 buf 为空还是 chan 没有 buf,都是一样的处理逻辑。此时会直接从 recvq 中取出第一个 g,然后把本次要发送的数据直接写给这个接收者 g,并调用 goready 把这个 g 唤醒。
接收
如果接收的时候发现 sendq 有 goroutine 正在等待,说明 buf 满了,或者 chan 是个非缓存 chan,根本没有 buf。对于接收来说 buf 满了或者 chan 没有 buf,二者的处理逻辑就不太一样了。因为需要保证顺序,buf 满了就不能直接去读 sender 的数据了,只能从 buf 中去。
- 如果是
buf满了:那么会先从buf中读一个值出来(腾一个位置出来),然后把 sender 发送的值写入buf,并唤醒这个 sender g。 - 如果是没有
buf的无缓存chan:那就直接把 sender 要发送的数据取出来,作为本次取到的数据,然后唤醒 sender g。
- 上一篇: Golang中的Map数据结构
- 下一篇: golang字符串4种拼接方式对比
如果您喜欢我的文章,请点击下面按钮随意打赏,您的支持是我最大的动力。
最新评论