Redis Scan基本使用
1. 基本介绍
由于 Redis 是单线程在处理用户的命令,而 Keys 命令会一次性遍历所有 Key,于是在命令执行过程中,无法执行其他命令。这就导致如果 Redis 中的 key 比较多,那么 Keys 命令执行时间就会比较长,从而阻塞 Redis。
所以很多教程都推荐使用 Scan 命令来代替 Keys,因为 Scan 可以限制每次遍历的 key 数量。
Keys 的缺点
- 没有 limit,我们只能一次性获取所有符合条件的 key,如果结果有上百万条,那么等待你的就是“无穷无尽”的字符串输出。
-
keys命令是遍历算法,时间复杂度是 O(N)。这个命令非常容易导致 Redis 服务卡顿。因此,我们要尽量避免在生产环境使用该命令。
相比于 keys 命令,Scan 命令有两个比较明显的优势:
-
Scan命令的时间复杂度虽然也是 O(N),但它是分次进行的,不会阻塞线程。 -
Scan命令提供了count参数,可以控制每次遍历的集合数。
可以理解为 Scan 是渐进式的 Keys。
Scan 命令语法
SCAN cursor [MATCH pattern] [COUNT count]
-
cursor- 游标。 -
pattern- 匹配的模式。 -
count- 指定每次遍历多少个集合。
大致用法如下:
SCAN 命令是基于游标的,每次调用后,都会返回一个游标,用于下一次迭代。当游标返回0时,表示迭代结束。
第一次 Scan 时指定游标为 0,表示开启新的一轮迭代,然后 Scan 命令返回一个新的游标,作为第二次 Scan 时的游标值继续迭代,一直到 Scan 返回游标为0,表示本轮迭代结束。
通过这个就可以看出,Scan 完成一次迭代,需要和 Redis 进行多次交互。
Scan 命令注意事项
- 返回的结果可能会有重复,需要客户端去重,这点非常重要。
- 遍历的过程中如果有数据修改,改动后的数据能不能遍历到是不确定的。
- 单次返回的结果是空的并不意味着遍历结束,而要看返回的游标值是否为零。
2. Scan 注意事项
使用时遇到一个特殊场景,跨区域远程连接 Redis 并进行模糊查询,扫描所有指定前缀的 Key。
如果直接开始 Scan,然后 Count 参数指定的是 1000。Redis 中大概几百万 Key。最后发现这个接口需要几十上百秒才返回。
原因分析
Scan 命令中的 Count 指定一次扫描多少 Key,这里指定为 1000,几百万 Key 就需要几千次迭代,即和 Redis 交互几千次,然后因为是远程连接,网络延迟比较大,所以耗时特别长。
最后将 Count 参数调大后,减少了交互次数,就好多了。
Count 参数越大,Redis 阻塞时间也会越长,需要取舍。极限一点,Count 参数和总 Key 数一致时,Scan 命令就和 Keys 效果一样了。
Count 大小和 Scan 总耗时的关系
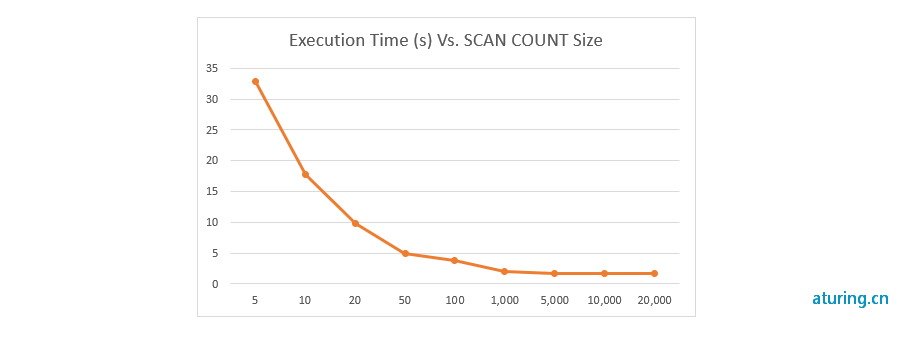
可以发现 Count 越大,总耗时就越短,不过越后面提升就越不明显了。
所以推荐的 Count 大小为 1W 左右。
如果不考虑 Redis 的阻塞,其实 Keys 比 Scan 会快很多,毕竟一次性处理,省去了多余的交互。
3. Scan 原理
Redis 使用了 Hash 表作为底层实现,原因不外乎高效且实现简单。类似于 HashMap 那样数组+链表的结构。其中第一维的数组大小为 2^n(n>=0)。每次扩容数组长度扩大一倍。
Scan 命令就是对这个一维数组进行遍历。每次返回的游标值也都是这个数组的索引。Count 参数表示遍历多少个数组的元素,将这些元素下挂接的符合条件的结果都返回。因为每个元素下挂接的链表大小不同,所以每次返回的结果数量也就不同。
演示
关于 Scan 命令的遍历顺序,我们可以用一个小例子来具体看一下:
127.0.0.1:6379> keys *
1) "db_number"
2) "key1"
3) "myKey"
127.0.0.1:6379> scan 0 MATCH * COUNT 1
1) "2"
2) 1) "db_number"
127.0.0.1:6379> scan 2 MATCH * COUNT 1
1) "1"
2) 1) "myKey"
127.0.0.1:6379> scan 1 MATCH * COUNT 1
1) "3"
2) 1) "key1"
127.0.0.1:6379> scan 3 MATCH * COUNT 1
1) "0"
2) (empty list or set)
如上所示,SCAN 命令的遍历顺序是:0 -> 2 -> 1 -> 3
这个顺序看起来有些奇怪,我们把它转换成二进制:00 -> 10 -> 01 -> 11
可以看到每次这个序列是高位加1的。
普通二进制的加法,是从右往左相加、进位。而这个序列是从左往右相加、进位的。
相关源码
v = rev(v);
v++;
v = rev(v);
将游标倒置,加一后,再倒置,也就是我们所说的“高位加1”的操作。
逆二进制迭代算法
Redis Scan 命令最终使用的是 reverse binary iteration 算法,大概可以翻译为 逆二进制迭代,具体算法细节可以看一下这个 Github 相关讨论.
这个算法简单来说就是:
依次从高位(有效位)开始,不断尝试将当前高位设置为 1,然后变动更高位为不同组合,以此来扫描整个字典数组。
其最大的优势在于,从高位扫描的时候,如果槽位是 2^N 个,扫描的临近的 2 个元素都是与 2^(N-1) 相关的就是说同模的,比如槽位 8 时,0%4 == 4%4, 1%4 == 5%4 , 因此想到其实 hash 的时候,跟模是很相关的。
比如当整个字典大小只有 4 的时候,一个元素计算出的整数为 5,那么计算它的 hash 值需要模 4,也就是 hash(n) == 5%4 == 1 ,元素存放在第 1 个槽位中。当字典扩容的时候,字典大小变为 8, 此时计算 hash 的时候为 5%8 == 5 ,该元素从 1 号 slot 迁移到了 5 号,1 和 5 是对应的,我们称之为同模或者对应。
同模的槽位的元素最容易出现合并或者拆分了。因此在迭代的时候只要及时的扫描这些相关的槽位,这样就不会造成大面积的重复扫描。
3 种情况
迭代哈希表时,有以下三种情况:
- 从迭代开始到结束,哈希表不 Rehash;
- 从迭代开始到结束,哈希表
Rehash,但每次迭代,哈希表要么不开始 Rehash,要么已经结束 Rehash; - 从一次迭代开始到结束,哈希表在一次或多次迭代中 Rehash。
即再 Rehash 过程中,执行 Scan 命令,这时数据可能只迁移了一部分。
因此,游标的实现需要兼顾以上三种情况。上述三种情况下游标实现的要求如下:
- 第一种情况比较简单。假设 redis 的 hash 表大小为 4,第一个游标为 0,读取第一个 bucket 的数据,然后游标返回 2,下次读取 bucket 2 ,依次遍历。
- 第二种情况更复杂。假设 redis 的 hash 表大小为 4,如果 rehash 后大小变成 8。如果如上返回游标(即返回 2),则显示下图:
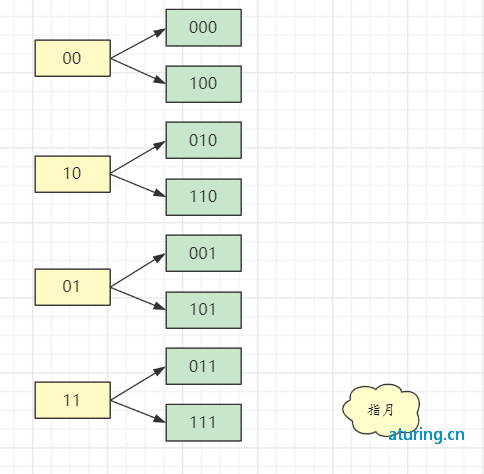
假设 bucket 0 读取后返回到 cursor 2,当客户端再次 Scan cursor 2 时,hash 表已经被 rehash,大小翻倍到 8,redis 计算一个 key bucket 如下:
hash(key)&(size-1)
即如果大小为 4,hash(key)&11,如果大小为 8,hash(key)&111。所以当 size 从 4 扩大到 8 时,2 号 bucket 中的原始数据会被分散到 2 (010) 和 6 (110) 这两个 bucket 中。
从二进制来看,size 为 4 时,在 hash(key) 之后,取低两位,即 hash(key)&11,如果 size 为 8,bucket 位置为 hash(key) & 111,即取低三个位。
所以依旧不会出现漏掉数据的情况。
- 第三种情况,如果返回游标 2 时正在进行 rehash,则 Hash 表 1 的 bucket 2 中的一些数据可能已经 rehash 到了的 Hash 表 2 的 bucket[2] 或 bucket[6],那么必须完全遍历 哈希表 2 的 bucket 2 和 6,否则可能会丢失数据。
Redis 全局有两个 Hash 表,扩容时会渐进式的将表 1 的数据迁移到表 2,查询时程序会先在 ht[0] 里面进行查找, 如果没找到的话, 就会继续到 ht[1] 里面进行查找。
游标计算
具体游标计算代码如下:
v |= ~m0; // 将游标v的unmarsked 比特都置为1
v = rev(v); // 反转v
v++; //这个是关键,加1,对一个数加1,其实就是将这个数的低位的连续1变为0,然后将最低的一个0变为1,其实就是将最低的一个0变为1
v = rev(v); //再次反转,即得到下一个游标值
代码逻辑非常简单,计算过程如下:

大小为 4 时,游标状态转换为 0-2-1-3。 当大小为 8 时,游标状态转换为 0-4-2-6-1-5-3-7。
可以看出,当 size 由小变大时,所有原来的游标都能在大 hashTable 中找到对应的位置,并且顺序一致,不会重复读取,也不会被遗漏。
总结一下:redis 在 rehash 扩容的时候,不会重复或者漏掉数据。但缩容,可能会造成重复但不会漏掉数据。
缩容处理
之所以会出现重复数据,其实就是为了保证缩容后数据不丢。
假设当前 hash 大小为 8:
- 第一次先遍历了 0 号槽,返回游标为 4;
- 准备遍历 4 号槽,然后此时发生了缩容,4 号槽的元素也进到 0 号槽了。
- 但是 0 号槽之前已经被遍历过了,此时会丢数据吗?
答案就在源码中:
do {
/* Emit entries at cursor */
de = t1->table[v & m1];
while (de) {
fn(privdata, de);
de = de->next;
}
/* Increment bits not covered by the smaller mask */
v = (((v | m0) + 1) & ~m0) | (v & m0);
} while (v & (m0 ^ m1));
具体计算方法:
v = (((v | m0) + 1) & ~m0) | (v & m0);
右边的下半部分是 v,左边的上半部分是 v。 (v&m0) 取出 v 的低位,例如 size=4 时 v&00000011
左半边 (v|m0) + 1 将 V 的低位设置为 1,然后 +1 将进位到 v 的高位,再次 &m0,V 的高位将被取出。
假设游标返回 2 并且正在进行 rehashing,大小从 4 变为 8,那么 M0 = 00000011 v = 00000010
根据公式计算的下一个光标是 ((00000010 | 00000011) + 1) & (11111111100) | (00000010 & 00000011) = (00000100) & (11111111100) | (00000000010) = (000000000110) 正好是 6。
4. 总结
-
ScanCount参数限制的是遍历的 bucket 数,而不是限制的返回的元素个数 - 由于不同 bucket 中的元素个数不同,其中满足条件的个数也不同,所以每次
Scan返回元素也不一定相同 -
Count越大,Scan总耗时越短,但是单次耗时越大,即阻塞 Redis 时间变长 - 推荐
Count大小为 1W 左右 - 当
Count = Redis Key 总数时,Scan和Keys效果一致 -
Scan采用 逆二进制迭代法来计算游标,主要为了兼容 Rehash 的情况 -
Scan为了兼容缩容后不漏掉数据,会出现重复遍历,即客户端需要做去重处理
核心就是逆二进制迭代法,比较复杂,而且算法作者也没有具体证明,为什么这样就能实现,只是测试发现没有问题,各种情况都能兼容。
- 上一篇: Redis基本数据结构
- 下一篇: postman使用进阶
如果您喜欢我的文章,请点击下面按钮随意打赏,您的支持是我最大的动力。
最新评论