MinerU 技术分享
视频介绍:
哔哩哔哩: https://player.bilibili.com/player.html?autoplay=false&bvid=BV1VD9FBoEob
1、项目概述
MinerU 是一个开源文档解析引擎,目标是把 PDF、图片、DOCX 等文档转换成适合机器处理的结构化结果,例如 Markdown、JSON、表格 HTML、公式 LaTeX 等。它的核心不是简单抽文本,而是恢复文档的阅读顺序、结构层级和版面语义。
截至 2026 年 4 月 21 日:
-
GitHub 仓库星标约
60.7k -
最新 release 为
mineru-3.1.1-released -
发布时间为
2026-04-17 -
许可证为
Apache 2.0
核心特性
-
支持
PDF、图片与DOCX、PPTX、XLSX输入 -
支持单栏、多栏和复杂版面解析
-
自动去除页眉、页脚、页码、脚注等干扰块
-
自动识别扫描版 PDF 和乱码 PDF,并切换 OCR
-
支持图片、表格、图表、印章、代码块、列表等内容块提取
-
公式输出为
LaTeX -
表格输出为
HTML -
OCR 支持 109 种语言
-
输出
Markdown、content_list.json、middle.json、可视化 PDF -
提供 CLI、FastAPI、Gradio WebUI、Router、OpenAI 兼容服务
版本说明
MinerU 当前已经进入 3.x 体系,3.0 之后最明显的变化不是单点功能增强,而是整体架构从单机工具转向服务化编排:
-
mineruCLI 变成基于mineru-api的编排客户端 -
mineru-api提供同步和异步解析接口 -
mineru-router负责多服务、多 GPU 统一入口 -
pipeline后端继续强化,支持纯 CPU -
DOCX原生解析正式进入主流程
2、主要功能
文档解析能力
-
恢复符合人类阅读顺序的文本
-
保留标题、段落、列表等结构
-
识别复杂排版中的块级关系
-
去除页眉页脚、页码、辅助文本等噪声
多模态内容提取
-
提取图片和图片描述
-
提取表格、表格标题和表格脚注
-
提取行间公式和行内公式
-
识别代码块、算法块、参考文献列表等结构
格式转换能力
-
公式转
LaTeX -
表格转
HTML -
文档转
Markdown -
结构化结果转
JSON
服务化能力
-
本地 CLI 直接解析
-
FastAPI 暴露 HTTP 接口
-
Gradio 提供可视化界面
-
Router 统一路由多个 worker
-
OpenAI 兼容服务支持远程
http-client模式
3、后端体系与整体架构
MinerU 当前主要有三类后端。
| 后端 | 特点 | 适合场景 |
|---|---|---|
pipeline |
速度快、稳定、低幻觉,可运行在 CPU 或 GPU | 单机验证、离线环境、资源有限场景 |
hybrid-auto-engine |
默认后端,结合文本抽取与模型能力,强调精度与稳定性平衡 | 大多数常规生产场景 |
vlm-* |
高精度,依赖 vLLM、LMDeploy、mlx 等推理后端 |
GPU 资源充足、追求复杂版面效果 |
架构分层
┌──────────────────────────────────────────┐
│ Access Layer 入口层 │
│ - mineru CLI │
│ - mineru-api │
│ - mineru-gradio │
│ - mineru-router │
│ - mineru-openai-server │
└──────────────────────────────────────────┘
↓
┌──────────────────────────────────────────┐
│ Engine Layer 解析引擎层 │
│ - pipeline │
│ - hybrid-auto-engine │
│ - hybrid-http-client │
│ - vlm-auto-engine │
│ - vlm-http-client │
└──────────────────────────────────────────┘
↓
┌──────────────────────────────────────────┐
│ Output Layer 输出层 │
│ - Markdown │
│ - content_list.json │
│ - content_list_v2.json │
│ - middle.json │
│ - layout.pdf / span.pdf │
└──────────────────────────────────────────┘
当前架构特点
-
mineru不再只是本地解析命令,而是 API 编排入口 -
mineru-api同时提供同步和异步接口 -
mineru-router负责多 worker 聚合和负载均衡 -
--api-url用于连接mineru-api -
--url用于连接 OpenAI 兼容服务
4、3.x 版本关键变化
DOCX 原生解析
-
3.0 正式支持
DOCX原生解析 -
不再依赖先转 PDF 再解析
-
在速度上相比传统流程有明显提升
pipeline 后端增强
-
README 给出
OmniDocBench v1.5分数86.2 -
官方说明精度超过上一代主流 VLM
MinerU2.0-2505-0.9B -
继续支持纯 CPU 场景
CLI / API / Router 编排升级
-
mineru未传--api-url时会自动拉起本地临时mineru-api -
mineru-api新增异步接口POST /tasks -
mineru-router提供与mineru-api兼容的统一入口
长文档与并发优化
-
滑动窗口降低长文档内存峰值
-
pipeline支持流式落盘 -
官方说明已完成线程安全优化
-
支持多线程并发推理和多卡部署
5、环境要求
| 维度 | pipeline | hybrid-auto / vlm-auto | hybrid-http-client | vlm-http-client |
|---|---|---|---|---|
| 纯 CPU 支持 | 是 | 否 | 是 | 是 |
| GPU 最低显存 | 4GB | 8GB | 2GB | 不需要 |
| 操作系统 | Linux / Windows / macOS | Linux / Windows / macOS | Linux / Windows / macOS | Linux / Windows / macOS |
| Python | 3.10 - 3.13 | 3.10 - 3.13 | 3.10 - 3.13 | 3.10 - 3.13 |
| 推荐内存 | 16GB 起,推荐 32GB | 16GB 起,推荐 32GB | 16GB 起 | 16GB 起 |
| 磁盘 | 20GB 以上,推荐 SSD | 20GB 以上,推荐 SSD | 至少 2GB | 至少 2GB |
补充说明:
-
Linux 仅支持 2019 年及以后发行版
-
Windows 因
ray兼容问题,仅支持 Python3.10~3.12 -
macOS 需使用
14.0+
6、安装方式
使用 uv / pip 安装
官方推荐:
pip install --upgrade pip -i https://mirrors.aliyun.com/pypi/simple
pip install uv -i https://mirrors.aliyun.com/pypi/simple
uv pip install -U "mineru[all]" -i https://mirrors.aliyun.com/pypi/simple
说明:
-
mineru[all]包含所有核心功能 -
适合大多数用户
-
兼容 Windows、Linux、macOS
通过源码安装
git clone https://github.com/opendatalab/MinerU.git
cd MinerU
uv pip install -e .[all] -i https://mirrors.aliyun.com/pypi/simple
如果只是想在本机先把流程跑通,尤其是 Mac 这类没有独立显卡的环境,可以先装 pipeline 相关依赖:
uv venv .venv --python 3.12
source .venv/bin/activate
uv pip install -e ".[pipeline]" -i https://mirrors.aliyun.com/pypi/simple
要演示 WebUI 时再把 gradio 加上:
uv pip install -e ".[pipeline,gradio]" -i https://mirrors.aliyun.com/pypi/simple
这样比一开始装 all 更稳一些。all 会把更多 VLM / 推理框架相关依赖带进来,对轻量验证不是必要项。
扩展模块安装
| 安装方式 | 命令 | 说明 |
|---|---|---|
| 核心功能 | uv pip install "mineru[core]" |
除 vllm/lmdeploy 外的核心能力 |
| vLLM 加速 | uv pip install "mineru[core,vllm]" |
适用于 VLM GPU 加速 |
| LMDeploy 加速 | uv pip install "mineru[core,lmdeploy]" |
适用于 VLM GPU 加速 |
| 轻量 client | uv pip install mineru |
适用于 vlm-http-client |
| pipeline client | uv pip install "mineru[pipeline]" |
适用于 hybrid-http-client |
注意:
-
不建议同时安装
vllm和lmdeploy -
如
vllm安装复杂,官方建议优先使用 Docker
7、模型源配置
MinerU 默认使用 HuggingFace 作为模型源。
切换到 ModelScope
适合大陆网络环境:
export MINERU_MODEL_SOURCE=modelscope
下载并使用本地模型
mineru-models-download
export MINERU_MODEL_SOURCE=local
mineru -p <input_path> -o <output_path>
说明:
-
不一定要手动下载。首次解析时,MinerU 会按当前模型源自动拉取需要的模型并缓存到本机
-
手动执行
mineru-models-download的价值是提前把模型准备好,避免现场演示或离线部署时临时下载 -
模型下载完成后,模型路径会写入用户目录下的
mineru.json -
也可以手动复制模板配置并修改模型目录
-
离线或私有化部署时,通常应选择
local
8、Docker 部署
使用 Dockerfile 构建镜像
wget https://gcore.jsdelivr.net/gh/opendatalab/MinerU@master/docker/china/Dockerfile
docker build -t mineru:latest -f Dockerfile .
Docker 方案特点
官方文档说明,MinerU 的 Docker 镜像基于 vllm/vllm-openai,默认集成:
-
vllm -
VLM 推理加速环境
-
相关依赖
使用 vllm 加速的前提:
-
GPU 为 Volta 及以后架构
-
可用显存不少于 8GB
-
宿主机驱动支持 CUDA
12.9.1+ -
容器能够访问宿主机 GPU
启动交互式容器
docker run --gpus all \
--shm-size 32g \
-p 30000:30000 -p 7860:7860 -p 8000:8000 -p 8002:8002 \
--ipc=host \
-it mineru:latest \
/bin/bash
端口说明:
-
30000:OpenAI 兼容服务 -
7860:Gradio WebUI -
8000:mineru-api -
8002:mineru-router
使用 Docker Compose 启动服务
下载 compose.yaml:
wget https://gcore.jsdelivr.net/gh/opendatalab/MinerU@master/docker/compose.yaml
启动 OpenAI 兼容服务
docker compose -f compose.yaml --profile openai-server up -d
启动 API 服务
docker compose -f compose.yaml --profile api up -d
文档地址:
http://<server_ip>:8000/docs
启动 Router
docker compose -f compose.yaml --profile router up -d
默认会使用 --local-gpus auto 在容器内拉起本地 worker。
启动 Gradio WebUI
docker compose -f compose.yaml --profile gradio up -d
访问地址:
http://<server_ip>:7860
Docker 部署注意事项
-
vllm会预分配显存 -
同一台机器通常不适合同时跑多个
vllm服务 -
如果做多服务部署,需要提前规划 GPU 资源
9、使用指南
这一部分可以直接按“本地跑通 → 服务化调用 → 看输出结果”的顺序演示。仓库里新增了一个目录:
usage_demos/
里面放了几组可改参数的样例:
| 文件 | 用途 |
|---|---|
00_install_pipeline.sh |
用源码安装一个偏轻量的 pipeline 环境 |
01_cli_pipeline.sh |
命令行解析本地 PDF |
02_start_api_pipeline.sh |
启动本地 mineru-api |
03_api_file_parse.py |
调用同步接口 /file_parse |
04_api_tasks_poll.py |
调用异步任务接口 /tasks 并轮询结果 |
05_start_gradio.sh |
启动 Gradio WebUI |
06_agent_flash_extract.sh |
Agent 免 Token 快速解析示例 |
07_agent_precision_extract.sh |
Agent Token 精准解析示例 |
agent_mcp_configs/ |
Claude / Cursor / streamable HTTP 的 MCP 配置示例 |
README.md |
演示步骤和参数说明 |
目录约定:
-
输入文件统一使用根目录下的
demo/ -
输出文件统一写到根目录下的
output/ -
不同调用方式用不同子目录区分,例如
output/cli_pipeline、output/api_file_parse、output/api_tasks、output/gradio
本地还没有安装时,可以在仓库根目录先执行:
./usage_demos/00_install_pipeline.sh
source .venv/bin/activate
如果要演示 WebUI:
EXTRAS=pipeline,gradio ./usage_demos/00_install_pipeline.sh
source .venv/bin/activate
对于配置较低的机器,建议只跑 pipeline模式,并且限制页数。不要刚上来就跑 hybrid-auto-engine、vlm-auto-engine 或大文档。
CLI 快速使用
最常见命令:
mineru -p <input_path> -o <output_path>
说明:
-
<input_path>支持本地PDF/ 图片 /DOCX -
<output_path>为输出目录 -
未传
--api-url时,会自动拉起本地临时mineru-api
常用参数
| 参数 | 含义 |
|---|---|
-p, --path |
输入文件路径或目录 |
-o, --output |
输出目录 |
--api-url |
MinerU FastAPI 服务地址 |
-m, --method |
auto / txt / ocr |
-b, --backend |
指定后端 |
-l, --lang |
指定语言,提升 OCR 准确率 |
-u, --url |
OpenAI 兼容服务地址 |
-s, --start |
开始页码,从 0 开始 |
-e, --end |
结束页码,从 0 开始 |
-f, --formula |
是否启用公式解析 |
-t, --table |
是否启用表格解析 |
常见示例
默认方式解析
mineru -p ./demo/pdfs/demo1.pdf -o ./output
使用 pipeline
mineru -p ./demo/pdfs/demo1.pdf -o ./output -b pipeline
本仓库新增的脚本已经把这条命令封装好了,默认只跑前 3 页:
./usage_demos/01_cli_pipeline.sh
也可以指定自己的文件和输出目录:
./usage_demos/01_cli_pipeline.sh ./demo/pdfs/small_ocr.pdf ./output/cli_small_ocr
默认输出目录是:
output/cli_pipeline
指定 OCR 语言
mineru -p ./demo/pdfs/demo1.pdf -o ./output -l en
指定页码范围
mineru -p ./demo/pdfs/demo1.pdf -o ./output -s 0 -e 9
关闭公式和表格解析
mineru -p ./demo/pdfs/demo1.pdf -o ./output -f false -t false
连接已有 API 服务
mineru -p ./demo/pdfs/demo1.pdf -o ./output --api-url http://127.0.0.1:8000
这里容易混淆两个参数:
-
--api-url连接的是 MinerU 自己的 FastAPI 服务,比如mineru-api或mineru-router -
-u / --url只在*-http-client后端里使用,连接的是 OpenAI 兼容推理服务
使用 vlm-http-client
mineru -p ./demo/pdfs/demo1.pdf -o ./output -b vlm-http-client -u http://127.0.0.1:30000
如果机器资源有限时,不建议把这条作为现场主路径。它更适合“本机只做 client,模型在远程服务上跑”的部署方式。
pipeline
pipeline 可以理解为 MinerU 的传统解析管线。它会做版面分析、文本抽取、OCR、表格和公式等处理,特点是资源要求相对可控,CPU / Apple Silicon 也能跑。缺点是复杂版面上限不如 VLM 路线。
export MINERU_MODEL_SOURCE=modelscope
export MINERU_PROCESSING_WINDOW_SIZE=16
export MINERU_API_MAX_CONCURRENT_REQUESTS=1
mineru -p ./demo/pdfs/demo1.pdf -o ./output -b pipeline -s 0 -e 2
*-auto-engine
auto-engine 表示“本机自动选择合适的本地推理引擎”。比如:
-
hybrid-auto-engine -
vlm-auto-engine
这里的重点是“模型在本机跑”。效果通常更好,但对显存、内存和推理框架要求也更高。hybrid-auto-engine 是当前 CLI 的默认后端,但默认不代表每台机器都适合跑。没有独立 GPU 或内存紧张时,先切到 pipeline 更实际。
*-http-client
http-client 表示“本机只发请求,推理交给远程 OpenAI 兼容服务”。比如:
-
vlm-http-client -
hybrid-http-client
典型链路是先在服务器启动:
mineru-openai-server --port 30000
然后客户端调用:
mineru -p ./demo/pdfs/demo1.pdf \
-o ./output \
-b hybrid-http-client \
-u http://127.0.0.1:30000
需要注意:vlm-http-client 本地更轻;hybrid-http-client 本地仍然需要一些 pipeline 依赖,因为 hybrid 不是把所有工作都丢给远程模型。
FastAPI 使用
启动服务:
mineru-api --host 0.0.0.0 --port 8000
本机演示建议绑定到 127.0.0.1,并把并发降下来:
./usage_demos/02_start_api_pipeline.sh
API 服务端中间结果默认写到:
output/api_server
核心接口:
-
GET /health -
POST /tasks -
POST /file_parse -
GET /tasks/{task_id} -
GET /tasks/{task_id}/result
异步提交示例:
curl -X POST http://127.0.0.1:8000/tasks \
-F "files=@demo/pdfs/demo1.pdf" \
-F "return_md=true"
更完整一点的异步调用可以直接跑:
python usage_demos/04_api_tasks_poll.py
默认下载结果目录:
output/api_tasks
它实际做了三步:
POST /tasks
GET /tasks/{task_id}
GET /tasks/{task_id}/result
这条链路适合放进业务系统:先提交任务,后面由任务状态驱动下载结果。
同步解析示例:
curl -X POST http://127.0.0.1:8000/file_parse \
-F "files=@demo/pdfs/demo1.pdf" \
-F "return_md=true" \
-F "response_format_zip=true" \
-F "return_original_file=true"
同步接口的 Python 示例:
python usage_demos/03_api_file_parse.py
默认解压结果目录:
output/api_file_parse
/file_parse 会等任务完成后再返回,适合调试、小文件、低频任务。文件一大或并发一高,还是异步任务接口更清楚。
特点:
-
POST /tasks立即返回task_id -
同步接口底层也走任务管理器
-
默认结果保留 24 小时
-
任务状态是单进程、进程内状态
Gradio WebUI
mineru-gradio --server-name 0.0.0.0 --server-port 7860
访问地址:
http://127.0.0.1:7860
本仓库中的脚本:
./usage_demos/05_start_gradio.sh
Gradio 结果默认写到:
output/gradio
如果已经启动了 mineru-api,可以让 WebUI 复用它:
MINERU_API_URL=http://127.0.0.1:8000 ./usage_demos/05_start_gradio.sh
Router
mineru-router --host 0.0.0.0 --port 8002 --local-gpus auto
特点:
-
对外接口与
mineru-api一致 -
可自动拉起本地 worker
-
也可通过
--upstream-url聚合多个已有mineru-api -
适合多服务、多 GPU 统一入口
OpenAI 兼容服务
mineru-openai-server --port 30000
然后使用:
mineru -p <input_path> -o <output_path> -b hybrid-http-client -u http://127.0.0.1:30000
说明:
-
vlm-http-client本地不要求安装torch -
hybrid-http-client需要本地具备pipeline相关依赖
10、Agent / Skills / MCP 接入
MinerU 现在不只是“人手动上传一个 PDF 再下载结果”的工具,它也在往 Agent 文档解析基础设施靠。官方生态仓库 MinerU-Ecosystem 里把接入方式分成几类:
-
CLI / SDK:业务系统或 Agent 直接调用
-
Skills:给 Agent 的操作说明,告诉它怎么选命令、怎么处理错误
-
MCP Server:让 Claude Desktop、Cursor、Windsurf 等客户端把 MinerU 当成工具调用
-
RAG 集成:LangChain、LlamaIndex、RAGFlow、Dify、FastGPT 等
Open API CLI
Agent 最容易接的是 CLI。这里用的是 mineru-open-api,和前面的本地开源 CLI mineru 不是同一个入口。
安装:
npm install -g mineru-open-api
或者:
go install github.com/opendatalab/MinerU-Ecosystem/cli/mineru-open-api@latest
检查:
mineru-open-api version
它有两个核心模式。
flash-extract
快速模式,不需要 Token,适合 Agent 第一次试探性解析小文件:
mineru-open-api flash-extract ./demo/pdfs/demo1.pdf \
--language ch \
--pages 1-3 \
-o ./output/agent_flash
本仓库脚本:
./usage_demos/06_agent_flash_extract.sh
这个模式的特点是启动成本低,但限制也明显:适合小文件和快速 Markdown 预览,不适合把表格、公式、多格式导出作为核心诉求。
extract
精准模式,需要 Token,适合生产、复杂版面、表格/公式、多格式导出:
mineru-open-api auth
或:
export MINERU_TOKEN="your-token"
然后:
mineru-open-api extract ./demo/pdfs/demo1.pdf \
--model pipeline \
--language ch \
--pages 1-3 \
--ocr \
--formula true \
--table true \
-f md,json \
-o ./output/agent_extract
本仓库脚本:
./usage_demos/07_agent_precision_extract.sh
如果文档版面很复杂,可以把模型改成 VLM:
MINERU_AGENT_MODEL=vlm ./usage_demos/07_agent_precision_extract.sh
如果需要更多格式:
MINERU_AGENT_FORMATS=md,json,html,docx ./usage_demos/07_agent_precision_extract.sh
Skills 接入
ClawHub 上已经有 MinerU Skill,安装命令很简单:
openclaw skills install mineru-ai
安装后,Agent 遇到文档解析任务时就可以按 Skill 里的规则调用 mineru-open-api。实际使用时,不需要专门记一堆参数,直接用自然语言描述任务即可,例如:
帮我用 MinerU 解析这个 PDF,输出 Markdown。
这个文档里有表格和公式,用 MinerU 精准解析,并保存到 output/mineru_skill。
如果只是小文件、快速转 Markdown,Skill 通常会走 flash-extract,不需要 Token;如果需要表格、公式、OCR、多格式导出或更大文件,就走 extract,需要先配置 Token:
mineru-open-api auth
也可以用环境变量:
export MINERU_TOKEN="your-token"
前提是本机已经能运行 mineru-open-api。如果还没安装,先执行:
npm install -g mineru-open-api
mineru-open-api version
MCP 接入
MCP 更像“工具协议”。配置后,支持 MCP 的客户端可以发现 MinerU 的工具,比如文档解析、OCR 语言列表查询、日志清理等。
stdio 模式配置示例,适合 Claude Desktop / Cursor 这类本地客户端:
{
"mcpServers": {
"mineru": {
"command": "uvx",
"args": ["mineru-open-mcp"],
"env": {
"MINERU_API_TOKEN": "your_token_here",
"OUTPUT_DIR": "/Users/w/ai/MinerU/output/mcp"
}
}
}
}
配置模板:
usage_demos/agent_mcp_configs/claude_desktop_config.example.json
usage_demos/agent_mcp_configs/cursor_mcp.example.json
如果客户端需要 streamable HTTP,可以单独启动:
MINERU_API_TOKEN=your-token ./usage_demos/agent_mcp_configs/start_streamable_http.sh
然后配置:
{
"mcpServers": {
"mineru": {
"type": "streamableHttp",
"url": "http://127.0.0.1:8001/mcp"
}
}
}
对应模板:
usage_demos/agent_mcp_configs/streamable_http.example.json
怎么选
| 接入方式 | 适合场景 | 备注 |
|---|---|---|
本地 mineru CLI |
本机离线验证、私有化、源码调试 | 模型跑在本机 |
mineru-api |
自己部署服务,业务系统 HTTP 调用 | 可控性强 |
mineru-open-api CLI |
Agent 自动化、云端 Open API | 分 flash-extract 和 extract |
| Skills | 让 Agent 知道怎么正确使用 CLI | 是策略和说明,不是服务 |
| MCP | Claude / Cursor / Windsurf 等工具化接入 | 更像标准工具接口 |
| LangChain / LlamaIndex | RAG 文档加载 | 直接进入向量化和检索链路 |
一个实际建议:
-
分享现场演示:先用本地
pipeline和 Gradio -
Agent 快速演示:用
mineru-open-api flash-extract -
生产 Agent:用
extract或 MCP,配 Token、输出目录和超时策略 -
私有化场景:用本地
mineru-api,由自己的 Agent 调 HTTP 接口
11、环境变量与调优参数
常用环境变量
| 环境变量 | 含义 |
|---|---|
MINERU_MODEL_SOURCE |
模型源,huggingface / modelscope / local |
MINERU_FORMULA_ENABLE |
是否启用公式解析 |
MINERU_TABLE_ENABLE |
是否启用表格解析 |
MINERU_TABLE_MERGE_ENABLE |
是否启用表格合并 |
MINERU_PROCESSING_WINDOW_SIZE |
单次处理窗口大小 |
MINERU_API_MAX_CONCURRENT_REQUESTS |
API 或 Router 的最大并发数 |
MINERU_API_OUTPUT_ROOT |
API 输出目录根路径 |
MINERU_API_TASK_RETENTION_SECONDS |
任务结果保留时长 |
MINERU_API_TASK_CLEANUP_INTERVAL_SECONDS |
任务清理间隔 |
MINERU_HYBRID_BATCH_RATIO |
hybrid 小模型 batch 倍率 |
MINERU_VL_MODEL_NAME |
指定远程模型名 |
MINERU_VL_API_KEY |
远程服务 API Key |
几个重要调优点
MINERU_PROCESSING_WINDOW_SIZE
-
影响长文档处理时的内存占用和吞吐
-
默认值为
64
MINERU_API_MAX_CONCURRENT_REQUESTS
-
影响 API / Router worker 最大并发请求数
-
默认值为
3
MINERU_HYBRID_BATCH_RATIO
用于控制 hybrid-http-client 显存占用,官方文档给出经验值:
| 单个 client 显存 | MINERU_HYBRID_BATCH_RATIO |
|---|---|
<= 6GB |
8 |
<= 4GB |
4 |
<= 3GB |
2 |
<= 2GB |
1 |
GPU 设备选择
官方建议使用 CUDA_VISIBLE_DEVICES 控制:
CUDA_VISIBLE_DEVICES=1 mineru -p <input_path> -o <output_path>
多卡示例:
CUDA_VISIBLE_DEVICES=0 mineru-openai-server --engine vllm --port 30000
CUDA_VISIBLE_DEVICES=1 mineru-openai-server --engine vllm --port 30001
CUDA_VISIBLE_DEVICES=0,1,2,3 mineru-router --host 127.0.0.1 --port 8002
12、输出文件说明
MinerU 的输出不只是 Markdown,还包括大量适合调试和二次开发的文件。
可视化文件
layout.pdf
-
展示每页布局分析结果
-
每个检测框右上角数字表示阅读顺序
-
适合检查版面分析和阅读顺序是否正确
span.pdf
-
仅适用于
pipeline -
用不同颜色标注文本片段
-
适合排查文本丢失、公式识别等问题
结构化文件
model.json
-
模型推理结果
-
包含类别、分数、bbox、顺序索引等信息
middle.json
-
最完整的中间结构
-
包含每页结果、页面大小、图片、表格、公式、丢弃块、分段块等信息
-
适合深度二次开发和精细质检
content_list.json
-
按阅读顺序平铺所有可读块
-
去掉复杂布局层次
-
保留块类型、页码、坐标
常见块类型包括:
-
text -
image -
table -
chart -
equation -
seal -
code -
list -
header -
footer -
page_number -
aside_text -
page_footnote
常见字段:
-
page_idx -
bbox -
text_level -
类型相关字段,如
table_body、image_caption
content_list_v2.json
-
3.0 起新增
-
顶层按页分组
-
每个块采用统一的
type + content结构 -
文档标注为开发中,后续格式可能调整
Markdown
-
适合人工检查和快速接入
-
不是最完整的数据结构
-
更适合作为展示层或初步验证结果
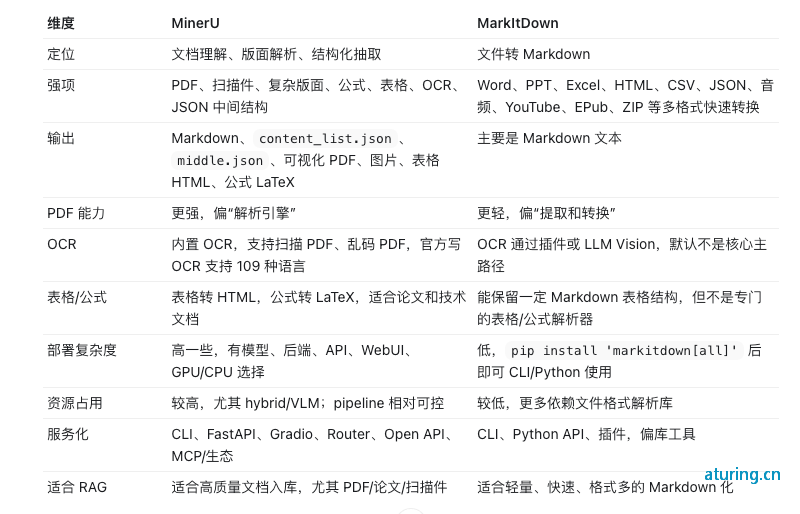
和makeitdown对比:
13、已知限制
MinerU 当前的主要限制包括:
-
极复杂版面下阅读顺序仍可能出错
-
竖排文本支持有限
-
复杂表格可能出现行列识别错误
-
布局模型对代码块支持还不完整
-
漫画、画册、小学教材、练习册等解析效果较差
-
一些冷门语言 OCR 可能误识别
-
部分公式在 Markdown 中渲染不正确
14、总结
MinerU 的核心不是“转文本”,而是“转结构”。 它解决的是复杂文档中的阅读顺序恢复、版面理解、表格与公式解析、OCR 兜底和结构化输出问题。
从当前版本看,MinerU 已经不是单纯的本地工具,而是一套完整的文档解析体系:
-
CLI 适合本地验证
-
API 适合服务化
-
Router 适合多服务和多 GPU 编排
-
Agent / Skills / MCP 适合把文档解析能力接进自动化工作流
-
Markdown 适合查看结果
-
JSON 和中间结构适合程序消费
如果做技术分享,最值得强调的三个点是:
-
3.x 的服务化架构变化
-
pipeline / hybrid / vlm三类后端的差异 -
content_list.json / middle.json这些结构化输出的价值 -
MinerU 从本地工具到 Agent 文档解析基础设施的演进
15、参考资料
-
官方首页:https://opendatalab.github.io/MinerU/zh/
-
使用指南:https://opendatalab.github.io/MinerU/zh/usage/
-
快速使用:https://opendatalab.github.io/MinerU/zh/usage/quick_usage/
-
命令行工具:https://opendatalab.github.io/MinerU/zh/usage/cli_tools/
-
命令行进阶参数:https://opendatalab.github.io/MinerU/zh/usage/advanced_cli_parameters/
-
模型源说明:https://opendatalab.github.io/MinerU/zh/usage/model_source/
-
Docker 部署:https://opendatalab.github.io/MinerU/zh/quick_start/docker_deployment/
-
扩展模块安装:https://opendatalab.github.io/MinerU/zh/quick_start/extension_modules/
-
输出文件说明:https://opendatalab.github.io/MinerU/zh/reference/output_files/
-
官方更新日志:https://opendatalab.github.io/MinerU/zh/reference/changelog/
-
GitHub 仓库:https://github.com/opendatalab/MinerU
-
GitHub Releases:https://github.com/opendatalab/MinerU/releases
-
MinerU 开发者生态:https://mineru.net/ecosystem
-
MinerU-Ecosystem:https://github.com/opendatalab/MinerU-Ecosystem
-
ClawHub MinerU Skill:https://clawhub.ai/mineru-extract/mineru-ai
- 上一篇: openclaw介绍及环境搭建
- 下一篇: 没有了
如果您喜欢我的文章,请点击下面按钮随意打赏,您的支持是我最大的动力。
最新评论